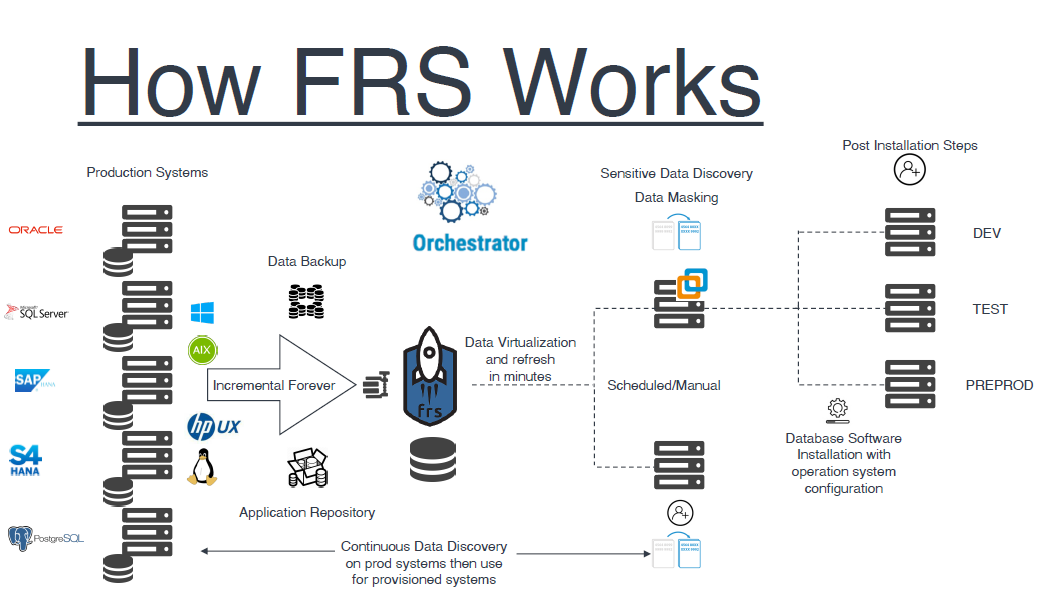
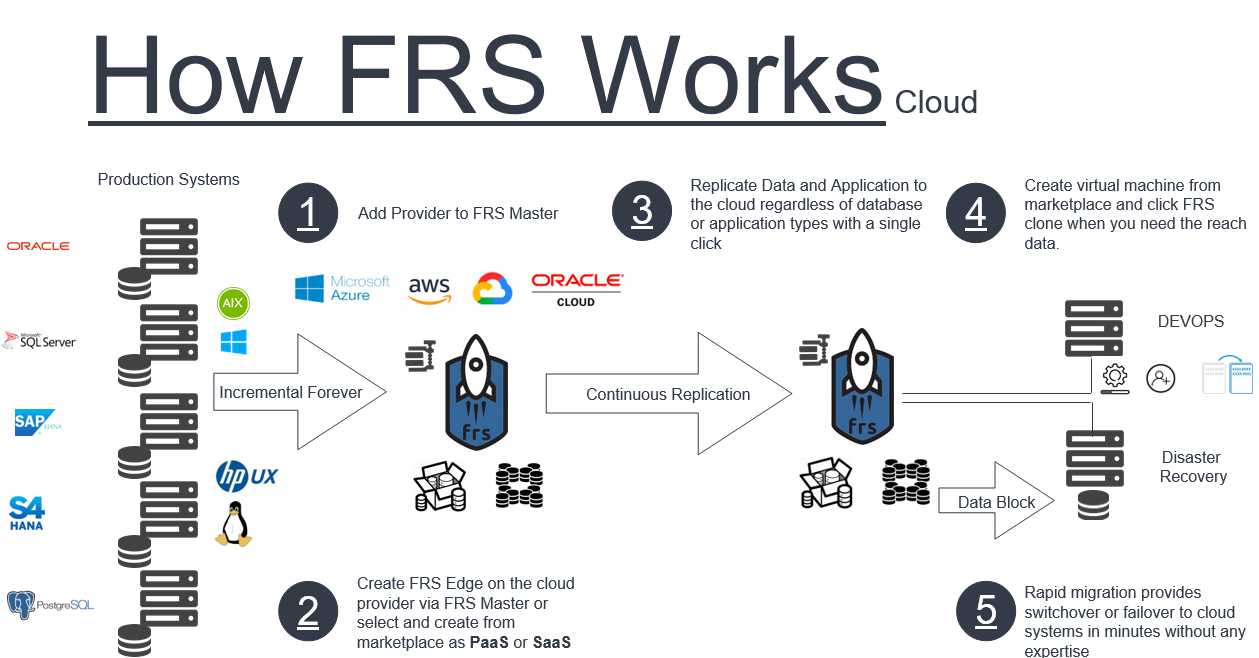
Oracle DB, MS SQL ve SAP HANA gibi kompleks veritabanlarının yönetimi

Oracle DB, MS SQL ve SAP HANA gibi kompleks veritabanlarını FRS nasıl yönetiyor
50 GB’lık bir veriyi kolaylıkla defalarca kopyalayabilirsiniz. Ancak 50 TB’lık bir veritabanınız varsa bir kopyalama işlemi birkaç gün sürebilir. Böyle bir veritabanının ilk full backup’ını aldıktan sonra, yalnızca blok değişikliklerini yedekleyerek devam edebilmek ise size farklı bir çözüm sağlayabilir.
Geleneksel yedekleme çözümlerinin de bir “incremental backup” konsepti var. Peki FRS’in farkı tam olarak nedir?
Geleneksel yedekleme metotlarında, haftalık full backup alındıktan sonra, veritabanı işlemleri, çoğunlukla günlük olarak kaydedilir ve bunlar incremental backup’lardır. Bu yaklaşımın birçok zorluğu vardır:
- Verileri kurtarırken, son full backup’ı geri yüklemeniz ve ardından incremental backup’ları “yürütmeniz” gerekir. Bu çok zaman alır ve uzun RTO’lara neden olur.
- Veritabanını full ve incremental backup’lardan yeniden oluşturmanız gerekir ve bu tüm verilerin bir yere kopyalanması gerektiği anlamına geliyor. Bu da ek bir depolama alanını gerektiriyor ve daha da kötüsü, kopyalama işlemi bitene kadar verilere erişemeyeceğiniz gibi, bu işlem günlerce sürebilir.
- Recovery süresi, son alınan full backup’tan ne kadar uzaklaşırsanız o kadar daha uzar, bu nedenle çoğu işletme haftalık full backup alarak bu sorunu çözmeye çalışıyor. Bu, bütün veri kopyalama işlemini 24 saat içinde tamamlayabilmek için ortamınızı (hosts, storage, network, vb.) buna göre “size” etmeniz gerektiği anlamına geliyor. Günümüzün veritabanlarının boyutuyla, bu genellikle uygulanabilir ve ekonomik bir seçenek değil.
- Son olarak, en kötü yanı, full backup almak uzun ve yoğun I/O gerektiriyor ve bu nedenle production veritabanınızın performansını olumsuz yönde etkiliyor. Neden tüm bu I/O bant genişliğini full backup yerine gerçek production ortamında kullanmıyorsunuz?
Peki, daha iyi bir çözüm nedir? Incremental değişiklikleri alıp ve point-in-time, hiçbir şeyi değiştirmek zorunda kalmadan anında kullanıma sunmaya izin veren bir sistem. Ve ideal olarak, başka bir yere kopyalamak zorunda kalmadan bu verilere hemen erişmenize olanak tanıyan bir yöntem. Günümüzde transactional veri tabanlarının çoğu “block storage devices” üzerinde bulunmaktadır ve bu cihazlardan nasıl snapshot alınacağı ister LVM gibi volume manager’lara sahip ana host üzerinde ister enterprise storage katmanı üzerinde olsun uzun zamandır bilinen yöntemlerdir. Bu nedenle, büyük veritabanları ile başa çıkmanın en verimli yolu snapshot’ları düzenli olarak almak ve zaman içinde noktalar arasındaki blok değişikliklerini takip etmektir.
Şimdi diyebilirsiniz ki, eğer bu kadar kolaysa, neden herkes bu çözümü sunmuyor? Bunun birçok nedeni var. Birincisi, production host veya storage katmanı üzerinde snapshot’ları düzenli olarak almak yeterli değildir. Gerçek bir backup’a sahip olmak için başka bir altyapı üzerinde bulunan bir şeye ihtiyacınız var ve bu snapshot’ları başka bir yere taşımak her zaman kolay değil. İkincisi, bu snapshot’lar storage katmanına özeldir – güncelleme yapmak ya da başka bir üreticiye geçmek istediğinizde sorun yaşayabilirsiniz. Bu nedenle ihtiyaç duyulan şey snapshot’lar arasındaki değişen blokları taşınabilir bir şekilde tanımlayan bir mekanizma – belirli bir noktadaki kopyaların ihtiyaç duyduğunuz yere taşınabildiği – DR için iş yeri dışında, uzun vadeli retention için bulutta ya da resiliency için başka bir bulut platformunda yani ihtiyaç duyulan her yerde.
Incremental-forever backup’a düzenli olarak devam edebilmeniz için üç şeye ihtiyacınız var:
- Bir snapshot’ın veri bütünlüğüne ve tutarlılığına sahip olması için veritabanını diskte tutarlı bir duruma getirmenin bir yolu.
- Başlangıçta bir full kopya ve daha sonra blok değişiklikleri olmak üzere, verileri almak için geçici, sabit bir kaynak olarak hizmet etmek için volume’lerin snapshot’larını almanın bir yolu.
- Zaman içinde iki nokta arasında blok değişikliklerini izlemenin bir yolu.

FRS’in üç ana veritabanını nasıl işlediğine bakalım: Oracle, Microsoft SQL Server ve SAP HANA.
Oracle, standart RMAN (Recovery Manager) yazılımı içerisinde yerleşik bazı özelliklere sahip. RMAN’ın veritabanının bir kopyasını bir görüntü olarak – ister full bir kopya ister sadece blok değişikliklerini – alma yeteneğinden yararlanmak, Oracle’ın işin zor kısmını sizin yerinize yaptığı anlamına gelir. Bu nedenle bazı üreticiler, incremental-forever Oracle backup’larını desteklediklerini iddia ediyor. Ancak tüm karmaşık Oracle ortamlarında uzmanlaşmak hala o kadar kolay değil. Bu nedenle tüm ihtiyaçlarınızın karşılandığından emin olmakta fayda var.
Örneğin, Oracle size blok değişikliklerini verirken, bunları anında kurtarmaya izin verecek şekilde de işlemeniz gerekir. Bunun için FRS, her yedeklemenin bir parçası olarak bir Oracle incremental merge işlemi başlatır, en son değiştirilen blokları alır ve Oracle’ın bunları önceki yedeklemeye uygulamasını sağlar. Elbette, bunu yapmadan önce önceki yedeklemenin snapshot’ını tutuyoruz, böylece sanal tam kopyalar olan ve anında erişime hazır bir dizi point-in-time snapshot elde ediyoruz. Bunu yaparken, logları ileriye doğru kaydırarak zaman içinde herhangi bir ana recovery yapabilmeniz için archive log backup’ları da yönetiyoruz.
Diğer bir karmaşıklık da, Oracle’ın veritabanı dosyalarını bir dosya sistemi üzerinde veya Oracle’ın depolamayı bir volume manager ve dosya sistemi olmadan doğrudan yönettiği Oracle Automatic Storage Management’ını (ASM) kullanarak çalıştırabilmesidir. FRS, her iki modu da tam olarak destekler ve production düzeninize uyabilir, host’u tercih ettiğiniz formatta yedekleme hedefi yani bir dosya sistemi veya bir ASM disk grubu olarak sunar. Bu, örneğin bir ASM veritabanını neredeyse herhangi bir kesinti olmadan kurtarmanıza olanak tanır, çünkü veritabanı çalışır durumdayken ASM rebalance işlemlerini kullanarak doğrudan bir ASM disk grubu olarak sunulan FRS yedeğinden çalışan bir veritabanını açabilir ve ardından verileri kullanmak istediğiniz herhangi bir depolama alanına taşıyabilirsiniz.
Microsoft SQL Server, blok değişikliklerini izlemek için Oracle ile aynı yerleşik mekanizmalara sahip değildir. Aslında, Oracle dşında başka hiçbir veritabanı bu özelliğe sahip değil. Dolayısıyla, SQL Server için sadece incremental-forever olarak, blok düzeyinde yedekleme yapmanın zorluğu biraz daha fazla. Microsoft, blok değişikliklerini kopyalamak için diskin o sağlam kopyasını almanın standart bir yolunu sağlayarak bize biraz yardım ediyor. Bu, Windows diskinin application consistent snaphot’ını oluşturan Shadow Copy olarak da bilinen Windows’un Volume Snapshot Service (VSS) ile elde edilir. Bu bize ihtiyacımızın yarısını verir. Ama hala hangi blokların değiştiğini tam olarak bilmemiz gerekiyor.
FRS, blok değişikliklerini elde etmek için Microsoft’un I/O stack’a erişebilen bir yazılımı olan filter drivers framework’ünden yararlanıyor. SQL Server dosyalarından herhangi birine yönlendirilen yazılan verilere bakıp ve bu dosyaların değişen bloklarını işaretliyoruz. Bu nedenle, bu dosyalar için, ilgili blok her değiştirildiğinde bir bitin ayarlandığı bir bit haritası tutuyoruz. Bu bit haritaları çok küçük ve etkilidir, bellekte bulunur ve bu nedenle tüm bu işlem çok hızlıdır ve host üzerinde ihmal edilebilir bir etkiye sahiptir. Yedekleme zamanı geldiğinde, diskin bir snapshot’ını oluşturmak için VSS’i ve ardından değişen dosya bloklarını kopyalamak için bitmap’imizi kullanıyoruz. SQL Server cluster ortamlarında, bu biraz daha fazla zaman gerektiriyor – bu bitmap’leri tüm host’larda tutuyoruz çünkü bir veritabanı yedekler ve host’lar arasında hareket edebilir. Böyle bir durumda, kopyalanması gereken bloklar, veritabanının çalıştığı tüm host’larda değişen tüm blokların bir toplamıdır. Tüm bunlar kullanıcı için otomatik olarak ele alınır.
SAP HANA, şu soruyu gündeme getiren bir bellek içi veritabanıdır: Bellek içi veritabanını, disk image’nın snapshhot’ını alıp değiştirilen blokları kopyalayabileceğiniz application-consistent bir duruma nasıl getirebilirsiniz? Neyse ki SAP, etkili yedekleme için bunun gerekli olduğunu fark etti ve veritabanını tutarlı bir duruma kurtarmak için gereken tüm verileri içeren bir storage snapshot framework oluşturdu. SAP HANA, Windows VSS’nin tam eşdeğeri olmayan ancak neredeyse her zaman Logical Volume Manager (LVM) ile kullanılan Linux üzerinde çalışır. Gerekli verileri kopyalamak için geçici, kararlı bir kaynak elde etmek için LVM’nin snapshot yeteneklerinden yararlanıyoruz, bu nedenle SAP ve LVM arasında incremental-forever backup için 3 gereksinimden 2’sini ele aldık.
Üçüncü şart, tabii ki, blok değişikliklerini izleyebilmektir. Yine, bunu yapmanın kolay ve evrensel bir yolu olmadığından, Linux için kendi değiştirilmiş blok izleme sürücümüzü geliştirdik. Linux sürücüsünün file level’dan ziyade volume level’daki değişiklikleri izlemesi açısından Windows sürücüsünden biraz farklı çalışır, ancak prensip olarak benzerdir. Yedekleme zamanı geldiğinde, bir storage snapshot hazırlanmak için SAP HANA’yı çağırıyoruz, temel volume snapshot oluşturmak için LVM’yi çağırıyoruz ve yalnızca değiştirilen blokları kopyalamak için bitmap’i kullanıyoruz. Değiştirilen veriler kopyalandıktan ve yedekleme tamamlandıktan sonra, artık gerekli olmadığı için bir dahaki sefere hangi bloğu kopyalamamız gerektiğini söyleyen LVM snapshot’ını kaldırıyoruz.
Önemli olan, bu işlemin (snaphot için tutarlı bir duruma getirilebildiği sürece) IBM Db2, MySQL, PostgreSQL, SAP ASE ve IQ, MongoDB, gibi herhangi bir veritabanına incremental-forever backup ve herhangi bir zamanda yedeğe neredeyse anında erişim ile uygulanabilmesidir.
100 TB’lık bir veritabanını her gün 2-3 saatte yedekleyerek, günler veya haftalar yerine dakikalar içinde kurtarma sürelerine sahip olmak günümüzde operasyonel, kaynak ve zaman maliyetleri açısından her sektördeki müşteriler için göz ardı edilemeyecek kazanımlar sağlıyor. Bu nedenle, seçtiğiniz veritabanı ne olursa olsun, FRS, veritabanı küçük, orta, büyük veya çok büyük (100+ TB), sadece incremental-forever olarak backup alacak şekilde destekler.
FRS vs LEGACY SYSTEMS

Yukarıdaki tablo bir müşterimizin veritabanı üzerinde gerçekleştirdiği işlemleri geleneksel yöntemler ve FRS ile gerçekleştirdiği zaman oluşan performans farklarını göstermektedir.
Veritabanı büyüklüğü 28 TB, mevcut yedekleme stratejisi haftada bir full ve günde bir incremental backup olup, bunlara ek olarak da 1x development, 1x test, 2x UAT ortamı bulunmaktadır. Herhangi bir problem anında veri kaybı süresi 1 gün ve veritabanının erişilebilir hale gelme süresi ise 18 saattir. Yedekleme ve Dev/Test ortamları için kullanılan toplam disk alanı 228 TB iken tek bir klonlama işlemi de 4 gün sürmektedir.
Aynı işlemler FRS ile yapıldığında veri kaybı süresi 20 dakika, veritabanın erişilebilir hale gelmesi ise veritabanı yazılımlarının kurulumu, yama testi vb. dahil olmak üzere 10 dakikada gerçekleşmektedir. Toplam kullanılan disk alanı 38 TB’a düşerken, tek bir klon çıkma işlemi kopya ortamlar açıldıktan sonrasında gerçekleştirilen zorunlu adımlar (SID, veritabanı erişim port numarası, veritabanı adı değiştirme, vb.) dahil olmak üzere 45 dakika sürmektedir.